스마트 캐스트
스마트 캐스트는 이름에서도 알 수 있듯이 자동으로 타입을 캐스팅 해주는 코틀린의 기능이다. 책에서는
$(1+2)+4$ 라는 수식을 평가하여 계산하는 프로그램의 코드를 예시로 들고 있다.
interface Expr
class Num(val value: Int): Expr
class Sum(val left: Expr, val right: Expr): Expr
fun eval(e: Expr): Int {
if(e is Num) {
val n = e as Num
return n.value
}
if (e is Sum) {
return eval(e.right) + eval(e.left)
}
throw IllegalArgumentException("Unknown expression")
}
fun main() {
println(eval(Sum(Sum(Num(1), Num(2)), Num(4))))
}
여기서 스마트 캐스팅이 발생하는 부분은 바로 e is Num 부분이다. 해당 if 블록 내에 진입했다는 것은 e가 Num임이 자명하므로, 명시적으로 타입을 변환할 필요가 없다.
실제로 IDE 상에서도 해당 부분에 경고를 띄우며, 생략 가능함을 알리는 것을 볼 수 있다.
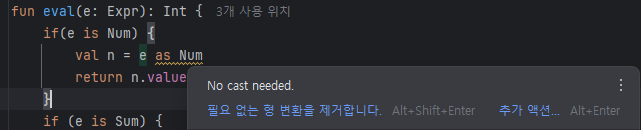
뿐만 아니라 IDE 상에서 if문에서 타입을 확인한 후 진입하면, 스마트 캐스팅 된 객체의 배경색을 다르게 표시해주는 기능도 있었다. 사진을 보면, if 블록 내의 e에 초록색 배경 하이라이팅이 되어있다. (그냥 하이라이팅인줄 알았는데 오늘 처음 알았다..)
if를 when으로 리팩터링하기
when이 if보다 좋은 이유는 무엇일까? 책에는 사실 이에 대해 자세히 나와있지 않다. 개인적으로 생각해본 이유는 바로 when을 사용하면 자동으로 모든 분기에 대해 커버됨이 보장되기 때문이라고 생각한다.
이에 대해서는 추후에 좀 더 자세히 정리해보려고 한다.
다시 돌아와서 위의 코드는 if문으로 되어있다. 가능한 조건을 각각 if문에 넣어 체크하는 로직이므로, 약간의 중복이 발생한다. (책에서는 이를 if 연쇄 라고 표현한다)
이러한 상황에서 when을 사용하면 코드를 꽤나 줄일 수 있다.
fun evalNew(e: Expr): Int =
when (e) {
is Num -> e.value
is Sum -> eval(e.right) + eval(e.left)
else -> throw IllegalArgumentException("Unknown expression")
}
여기서도 마찬가지로 각 분기 뒤의 코드에서 자동으로 스마트 캐스팅이 이루어지므로 같은 when 블록의 e 객체라도, 타입 캐스팅 없이 자유자재로 상황에 맞게 사용할 수 있는 것을 확인할 수 있다.
if, when의 분기에서 블록 사용하기
분기에 블록을 사용한다는 것은 무슨 뜻일까?
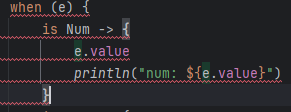
fun evalWithLogging(e: Expr): Int =
when (e) {
is Num -> {
println("num: ${e.value}")
e.value
}
is Sum -> {
val left = evalWithLogging(e.left)
val right = evalWithLogging(e.right)
println("sum: $left + $right")
left + right
}
else -> throw IllegalArgumentException("Unknown expression")
}
해당 함수는 식 본문 함수이므로, when의 결과 값이 함수의 반환 값이된다. Num일 때를 예시로 들면, 아까는 단순히 e.value라는 식 하나만 존재했지만, 위에 println() 메서드를 추가해버렸다.
처음 코틀린을 공부할 때, 처음에는 잘못된 문법인 줄 알았다. 블록 전체를 리턴하는 것으로 생각했기 때문이다. 하물며 e.value 앞에 return도 없다..
결론적으로 코틀린의 블록은, 값을 만들어내야 하는 경우 블록의 마지막 '식'이 블록의 결과이다.
사실 이 책을 보기 전까지도 컴파일러가 해당 블록을 본 다음에 알맞은 반환값을 잘 골라서 던져준다고 생각했다. 때문에 e.value가 굳이 맨 뒤에 있어야하나? 하고 바꿔봤는데 바로 에러가 발생했다..
추가적으로 주의할 점은 블록 본문 함수같은 경우엔, 내부에 명시적인 return 문이 반드시 있어야하므로 블록을 리턴값으로 사용할 수 없다.
또한 이는 개인적인 생각이지만, 해당 방법은 읽는 사람에게 하여금 return 될 식을 찾게 만드는 약간의 가독성의 아쉬움이 있는 방법이기에 많이 사용할 것 같지는 않다고 생각한다.
대상 이터레이션: while과 for 루프
코틀린의 이터레이션은 자바, C# 등의 다른 언어에서 사용하는 방법과 아주 비슷하다고 책에서 소개하고 있다. 이에 대해서는 나 또한 실제로 사용하면서 그렇게 느꼈던 것 같다.
while(조건) {
/*...*/
if (shouldExit) break
}
do {
if(shouldSkip) continue
/*...*/
} while (조건)
while문과 do while문은 여느 언어와 비슷하게 사용하면 된다. while문은 조건식이 참인 동안 본문을 반복 실행하고, do while문은 조건에 상관없이 우선 do 블록이 1회 실행된다.
break, continue 또한 기존에 알던 그것들과 동일하다. 여러 겹의 반복문에 대해 break나 continue를 적용할 때에도 현재 위치해있는 레벨의 반복문에만 적용되기 때문에
다른 언어들 처럼 플랙을 사용하여 조작하거나, 라벨링을 통해 해당 레벨의 루프를 조작할 수 있다.
outer@ while(outerCondition) {
while (innerCondition) {
if (shouldExitInner) break
if (shouldSkipInner) continue
if (shouldExit) break@outer
if (shouldSkip) continue@outer
}
}수에 대한 이터레이션
책에서는 다음과 같이 소개하고 있다.
코틀린에서는 고전적인 for루프를 사용하지 않는다. (int i = 0; i < 10; i++) 이 대신에 코틀린에서는 범위를 사용한다.
범위는 다음과 같이 사용할 수 있다.
for (i in 1..100) {
println(i)
}
위의 코드에서 1..100은 range로 1, 100을 포함하며 1씩 증가한다.
for(i in 100 downTo 1 step 2)
for(i in 1 ..< 100)
for(i in 1 until 100)
첫 번째 예시는 역방향으로 범위를 선언하는 것과, 증가/감소 값의 절댓값을 step을 통해 지정해 줄 수 있음을 나타낸다
두 번째, 세 번째 예시는 100을 포함하지 않는 범위를 선언하는 방법을 나타낸다.
컬렉션에 대해 이터레이션
코틀린 이전에 C++, 파이썬을 사용할 때 for (x: y), for(x in y) 형태의 이터레이션을 사용한 기억이 있다. 코틀린의 경우에도 for(x in y) 형태의 이터레이션을 채택하고 있고, 책에서는 이 형태의 루프를 가장 자주 쓴다고 언급하고 있다.
fun main() {
val collection = listOf("red", "green", "blue")
for (color in collection) {
print("$color ")
// red green blue
}
}
또한 코틀린은 구조 분해 구문을 지원한다.
fun main() {
val binaryReps = mutableMapOf<Char, String>()
for (c in 'A'..'F') {
val binary = c.code.toString(radix = 2)
binaryReps[c] = binary
}
for ((letter, binary) in binaryReps) {
println("$letter = $binary")
}
}
binaryReps는 Char, String의 쌍으로 이루어진 맵이다. 그런데 이를 다루고 있는 for문에서 Map의 entry를 두개로 나눠 사용할 수 있는 것을 알 수 있다.
뿐만 아니라 인덱스 기반의 다른 컬렉션에서도, withIndex를 사용하여 컬렉션의 원소와 인덱스를 함께 다룰 수 있다.
fun main() {
val list = listOf("10", "11", "1001")
for ((index, element) in list.withIndex()) {
println("$index: $element")
}
}
생뚱맞은 이야기지만, 지금까지의 in이 어떤 의미로 사용되었는지 생각해보면, 컬렉션이나 범위를 순회하기 위해 사용되었다는 것을 알 수 있다. 책에서는 바로 다음에 in에 대한 다른 비슷하지만 다른 쓰임을 소개하고 있다.
in을 컬렉션이나 범위의 원소 검사에 사용하기
fun isLetter(c: Char) = c in 'a'..'z' || c in 'A'..'Z'
fun isNotDigit(c: Char) = c !in '0'..'9'
fun main() {
println(isLetter('q'))
println(isNotDigit('x'))
}
이전까지 사용된 in의 맥락으로 생각했을 때는 c in 'a' .. 'z' 는 a부터 z까지의 알파벳을 c에 순차적으로 넘겨준다는 의미로 생각되어야 하지만, 여기서는 반복이 아니라 포함 여부를 검사하게 된다.
뿐만 아니라 부정(!)을 in앞에 붙여 불포함 여부를 검사할 수도 있다.
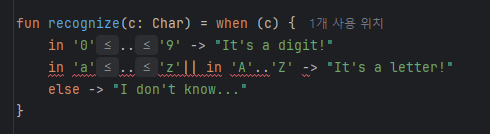
fun recognize(c: Char) = when (c) {
in '0'..'9' -> "It's a digit!"
in 'a'..'z', in 'A'..'Z' -> "It's a letter!"
else -> "I don't know..."
}
fun main() {
println(recognize('8'))
}
해당 예제는 when문에서 in을 사용하는 예제이다. 개인적인 생각으로 when문에서 in을 자주 사용했던 것 같다. 주목할만한 점은 범위 조건을 여러개 지정할 수 있다는 것이다.
나도 이 책에서 처음 본 문법이었는데 단순히 생각했을 때, or연산자( || )를 사용하면 되지 않을까? 해서 바꿔봤는데 막상 사용하면 오류가 발생한다.
코틀린에서 예외 처리: throw, try, catch, finally
책에서는 코틀린의 예외 처리는 자바, 다른 언어의 예외 처리와 비슷하다고 설명하고 있다.
예외처리에 대해 간단히 짚고 넘어가자면, 예외처리는 프로그램이 비정상 상황을 맞닥뜨렸을 때, 그냥 종료되거나, 런타임 에러가 발생하는게 아니라, 로그를 남기거나, 다시 시도하거나, 사용자에게 안내하는 등 대응의 여지를 남길 수 있도록 하는 것이라고 생각한다.
체크 예외와 언체크 예외
자바에서는 체크 예외를 메서드 시그니처의 일부로 사용한다고 한다.
Integer readNumber(BufferedReader reader) throws IOException
위 예제는 자바의 예제인데, 자바에서는 함수를 작성할 때 함수 선언 뒤에 throws IOException을 붙여야 한다. 이는 IOException이 체크 예외이기 때문인데, 체크 예외는 반드시 명시적으로 처리해야만 하는 유형의 예외이다.
반대로 언체크 예외는 명시적으로 처리하지 않아도 된다.
이에 대해서는 추후 더 자세히 정리하려고 한다.
예외 던지고 잡아내기
예외를 던지고 잡아내고 싶을 때, 다른 언어들 처럼 코틀린도 try, catch를 사용할 수 있다.
'Kotlin' 카테고리의 다른 글
| Kotlin in action 2/e: 함수 정의와 호출(2) 로컬 함수, 코드를 확장 함수로 추출하기 (0) | 2026.02.09 |
|---|---|
| Kotlin in action 2/e: 함수 정의와 호출(1) joinToString() 함수 직접 구현 (0) | 2026.02.07 |
| Kotlin in Action 2/e: 코틀린 기초(1): 함수, 변수, 클래스, 프로퍼티, 이넘, when() (0) | 2026.02.05 |
| Kotlin in Action 2/e: 코틀린 코드의 컴파일 (0) | 2026.02.05 |
| Kotlin in Action 2/e: 책 소개 및 서론 (0) | 2026.02.04 |